What's going on with the event study in Moretti (2021)?
An explainer for economists

If you’re reading Moretti (2021) (M21) after seeing my comment, you’re probably confused by the Figure 6 event study. The idea is to test whether cluster size affects patenting, using variation in cluster size from inventors who move across cities: “this specification is an event study, based on a “pure” movers design solely exploiting variation in cluster size induced by moves.” (p.3352) So the event is moving, and the treatment is the change in cluster size (i.e., the number of other inventors in the same research field and city).
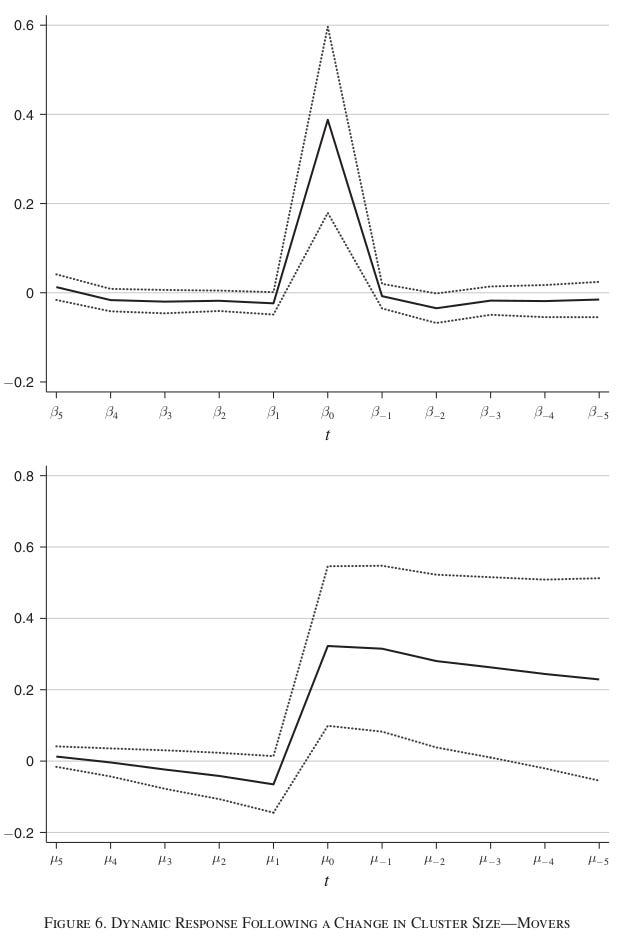
But why are there two panels? An event study gives us only one set of coefficients, i.e., the treatment effect in each event year. What does the spike in Figure 6a mean? Why isn’t t=-1 omitted as the reference year? What’s going on with the x-axis labels?
To explain this, let’s go back to Figure 5 (which happens to look very similar to Figure 6). M21 is running a regression of log patents (y) for inventor i on current log cluster size (S) as well as five leads and five lags of cluster size. Here’s M21 Equation 2:
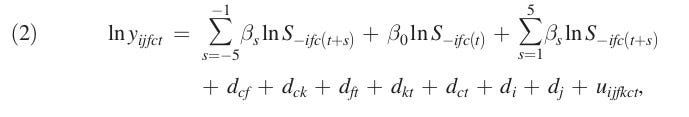
The lead terms (B_1 to B_5) capture how current patenting is affected by future cluster size, while the lag terms (B_{-5} to B_{-1}) capture lagged effects of past cluster size. M21 says this is “studying the dynamic response of productivity following a change in cluster size”, but also that “this is not a standard event study”. (p.3351)
Thanks to Schmidheiny and Siegloch (2023), we know that this is a distributed lag model. They prove that event study (ES) and distributed lag (DL) models are equivalent.1 But ES models give you estimates of the cumulative effect of a treatment, and DL models give you the incremental effect, i.e., changes in the cumulative effect. So the DL estimates need to be aggregated to get the total treatment effect. In M21 Fig 5, the beta terms are the incremental effects and the mu terms are the aggregated cumulative effect.2
Moreover, this is the most extreme case of a DL model. Cluster size is a continuous variable and changes every year, so this is equivalent to an event study where a different event occurs every year (i.e., a change in cluster size). The simplest case is a binary treatment that turns on once; here we have a time-varying continuous treatment dose. M21 does not discuss the identifying assumptions required here.
Now let’s revisit the event study in Figure 6. M21 seems to think that this is also a DL model, with incremental beta estimates in the top panel and aggregate mu estimates in the bottom panel. The spike in Figure 6a is exactly what a proper treatment effect looks like in a DL model, where there is an incremental effect in the treatment year, and nothing in other years. But this is wrong: an event study already gives us aggregate treatment effects, so aggregating again means calculating the cumulative response function of a cumulative effect. So Figure 6b is meaningless and should be removed.
And the text clearly states that Figure 6 is attempting an event study, based on interacting a treatment variable with event time indicators:
In Figure 6 I replicate [Figure 5] using only variation from inventors who move across cities. [...] I use the subset of inventors who change city once to estimate a variant of equation (2), where t = 0 marks the time of the move, and the timing relative to an inventor’s move is interacted with the corresponding cluster size before the move and after the move. [...] Thus, this specification is an event study, based on a “pure” movers design solely exploiting variation in cluster size induced by moves.” (p.3352)
But as I discuss in my comment, this is not a proper event study specification. Instead of using the change in cluster size associated with moving across cities, M21 interacts pre-move average cluster size with the pre-move event time indicators, and post-move average cluster size with the post-move event time indicators. M21 doesn’t show a regression equation; my reconstruction is:
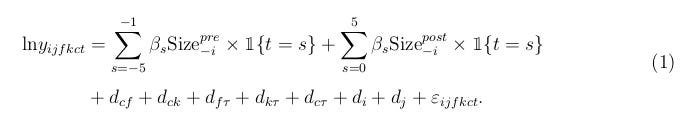
But this doesn’t use variation in cluster size from moving; it is identified even if there is no change in size (Size_pre = Size_post). In my comment, I show that a correct mover event study using ∆Size = Size_post - Size_pre as the treatment variable gives a null result.
So why does Figure 6a have that spike in t=0? Equation 1 is not using variation from moving, so there shouldn’t be a spike. This specification is actually testing for heterogeneity in the cross-sectional relationship between (averaged) cluster size and patenting by event time. So the beta coefficients should all be equal, if they estimate the same constant elasticity.
The problem is that the M21 code does not follow my Equation 1 above, due to a coding error. It doesn’t generate an interaction of Size_post with the event time indicator for t=0, but instead uses the regular time-varying cluster size variable (ln S_it). So B_0 is estimated using data from all event years, instead of capturing the effect in t=0. In Figure A1 of my comment, I show the results using the original and corrected code. The large spike disappears:
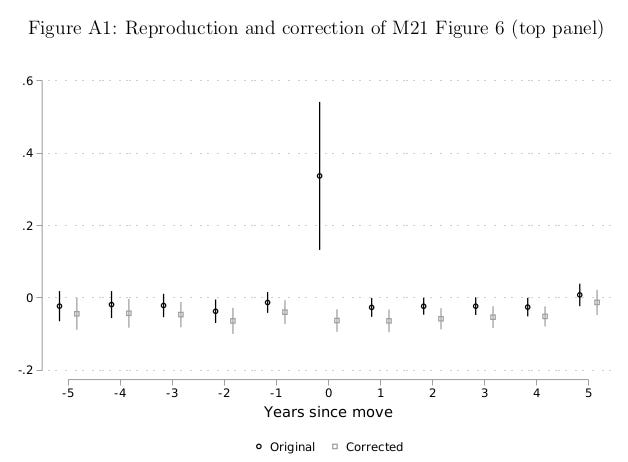
To sum up: M21 Figure 6 shows an attempted event study that is confused with a distributed lag model. Figure 6b calculates the cumulative response function of a cumulative effect, and is unnecessary. Figure 6a uses an incorrect event study specification, and the large effect is due to a coding error anyway.
Why does a regression on leads and lags do the same thing as an event study, which interacts the treatment variable with event time indicators? Consider a binary treatment T and a DL model with one lead and one lag; suppose the treatment occurs in t=2000, so T=0 before 2000 and T=1 afterwards. Then (ignoring other terms) Y_2000 = B_{-1} T_1999 + B_0 T_2000 + B_1 T_2001 = B_{-1} x 0 + B_0 x 1 + B_1 x 1 = B_0 + B_1. And Y_1999 = B_{-1} T_1998 + B_0 T_1999 + B_1 T_2000 = B_{-1} x 0 + B_0 x 0 + B_1 x 1 = B_1. So B_0 contributes to the estimate in event year 0 (t=2000), and not in event year -1 (t=1999). Hence, the incremental effect of the treatment (B_0) is identified off of the change between event years -1 and 0. This is the same as B_0 from an event study.
M21 calculates the aggregate effects incorrectly. Schmidheiny and Siegloch (2023) says to omit t=-1 as the reference period, and calculate the cumulative effects by (1) cumulating the post-treatment effects upwards and (2) cumulating the pre-treatment effects downwards with a negative sign. M21 simply sums all of the incremental effects, with no reference period.