Moretti replication published in AER
How I found ten problems in a paper from a top economics journal

I’m pleased to announce that my replication of Moretti (2021) (M21) is now accepted as a comment at American Economic Review. Here is the pdf. I find ten issues in the paper. My comment focuses on two major problems; in the appendix, I document eight (relatively) minor problems.
M21 studies agglomeration effects for innovation: do bigger technology clusters have more patenting? The main results are based on inventor-level regressions of patents on cluster size, which give a positive correlation. To claim a causal effect, M21 uses an event study and IV strategy to rule out selection and omitted variable bias.
To test for selection bias, M21 uses an event study based on inventors moving across cities. Since moving changes cluster size, we should see a clear effect on patenting; if inventors select into bigger cities, we’ll see a trend before the move. I show that the original event study uses an incorrect model: it doesn’t actually use variation from moving. When I run a proper mover event study, I get a null result.


M21 uses an instrumental variable to address omitted variable bias, such as local subsidies that drive both cluster size and patenting. The instrument is based on the number of inventors in the same field who work for firms in other cities. Due to a coding error, the data is not sorted by city, so the instrument is constructed incorrectly. I correct the code and find a null result.

The event study and IV are necessary to establish that the baseline regressions show causation, nor correlation. Since they both fail, the main takeaway of my comment is that the positive correlation between cluster size and patenting may not be causal.
I was hired by Coefficient Giving to do a small extension of this paper, since it’s the main evidence on technology agglomeration effects that informs their housing policy funding. But the more I looked at the paper, the more problems I found. Let’s go through the other eight problems:
Issue 3: Early on, I would sometimes get different results when running the baseline regression to get the main patenting-size elasticity. It turns out this is due to M21 using many-to-many merges in the data cleaning, so the results are actually unreproducible. Each time you run the code, you get a slightly different sample.

Issue 4: Table 6 studies the effect of cluster size on patent quality, measured using citations. M21 claims to use log citations, but the code actually does log(y+0.00001). When I use log(y+1) or Poisson, the effect switches from positive to negative.
As in Chen and Roth, this happens because the extensive margin effect is positive, and a smaller constant puts less weight on the intensive margin effect. Here, c=0.00001 means valuing the extensive margin as a 40,000% change in the intensive margin.
M21 also calculates citation- per-patent using citations-per-coauthor and patents-per-coauthor; but this nullifies the per-coauthor adjustment. The correct approach is to use citations per coauthor / whole patents.
So the original M21 finding is reversed: patent quality is in fact decreasing in cluster size. The actual story may be: larger clusters produce more patents, but they are lower quality, e.g., strategic patents used in IP lawsuits. (For example, bigger firms produce strategic patents and locate in big cities.)
Issue 5: there’s another substantive coding error when M21 estimates heterogeneous elasticities by cluster size in Table 8. Here the goal is to test whether agglomeration effects are bigger in bigger clusters. M21 reports limited heterogeneity.
M21 interacts log cluster size with size quartile indicators, but incorrectly omits the quartile indicators themselves. This forces the baseline level of patents to be equal across quartiles, biasing the estimates. When I do the correct interaction, I find substantial heterogeneity across size quartiles. The patenting-cluster size elasticity is actually much bigger in large clusters.
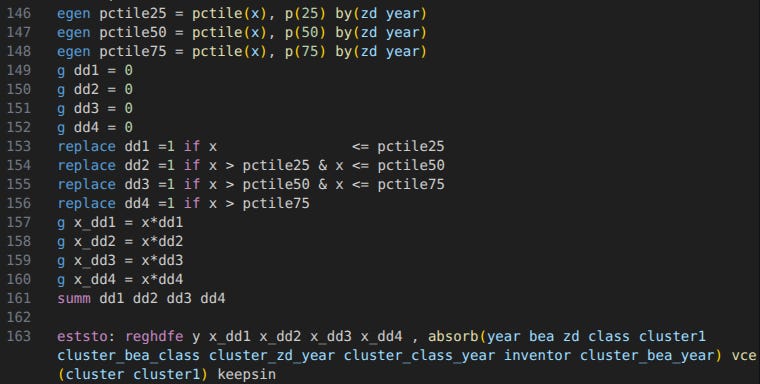
M21 does an exercise to quantify the aggregate benefits of agglomeration. The idea: equalize cluster size and calculate the decrease in the total number of patents. Since inventors are reallocated to smaller clusters, total output falls. But since M21 understates the heterogeneity in elasticities by size quartiles, M21 also understates the aggregate effects. The aggregate losses appear to be 3x larger!
But this isn’t the final word. First, the elasticity may not be causal. Second, we need to account for the negative effect on patent quality. When I redo the exercise using quality-adjusted patents, I find a similar aggregate loss as the original. (See appendix fn.32)
Issue 6: M21 uses a distributed lag model in Figure 5, regressing log patents on five leads and five lags of log cluster size. This is a demanding model, and M21 doesn’t discuss identifying assumptions. (More discussion here.)
There’s another coding error: M21 defines leads and lags using Stata’s _n operator, which refers to the observation number. But with an unbalanced panel, the previous observation is not the previous year. (You should use the panel operators L. and F.) When I fix the code, the estimate loses significance.
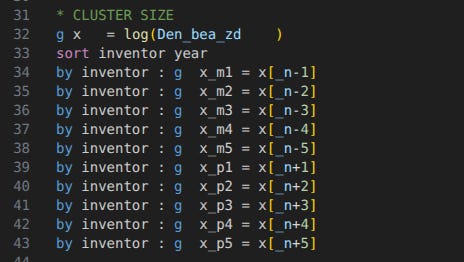
This also applies to Fig A1, which restricts to the subset of pharmaceutical patents. When I correct the code, the sample size drops to N=58, so the regression fails entirely. Moreover, the M21 code doesn’t even match the published figure: there’s no B_0 term in Fig A1, but it’s there when I run the original code. But Fig A1 is based on Equation 2, which clearly has B_0.


Issue 7: M21 Table A.8 tests whether the elasticity is larger in higher-quality clusters. There are two issues here: the code is supposed to use modal cluster size, but M21 now takes average size. And M21 doesn’t adjust for team size, when the main results use fractional attribution for coauthored patents. After correcting, the estimates are half as large.
Issue 8: M21 varies the time unit of the data, from 1-month to 3-year periods. The idea, according to M21, is to address missing observations; when inventors do not patent, they don’t have a row in the data. M21 claims this creates a downward bias at shorter time units, because more of the extensive margin effect is missing.
This interpretation is incorrect. Regardless of the time unit, there are no observations with patent=0, so no extensive margin effect can be estimated. Moreover: at shorter time units, coauthors make up a bigger share of cluster size, and patents-per-coauthor is mechanically linked to the number of coauthors. This creates a mechanical negative bias.
Issue 9: M21 claims that controlling for team size (number of coauthors on a patent) increases the elasticity. This is incorrect: patents are already measured on a per-coauthor basis, so adjusting for team size again means controlling for the same variable twice.
This is especially confused. Team size is not a confounder, but a mediator: cluster size affects patenting directly, and indirectly by enabling larger teams, where team size independently affects patenting. Controlling for a mediator means shutting down the causal pathway we’re trying to estimate.
Issue 10: When inventors do not patent in a year, they don’t have a row in the data; we know they have zero patents, but their city is unobserved. M21 interpolates these observations for gaps of 1 or 2 years, to capture part of the extensive margin effect.
There’s a coding error: for two-year gaps, only the second year of the gap is filled. Fixing this increases the elasticity, since more observations are interpolated, leading to a bigger extensive margin.
So there are a lot of issues in M21. The major ones are the event study and IV, the citation results, and the heterogeneity by cluster size. Should you believe in agglomeration effects for innovation? My advice: don’t update too much on this paper. (Although I do have ideas on how to fix it.)
I started working on this 3 years ago. I emailed Moretti about the event study in July 2023, and never got a response. But he was a referee at AER and offered some useful feedback. It would have been helpful for Coefficient Giving to get this feedback sooner!
This has happened to me several times now, where the author never responds to questions. If you publish research, and it’s actually being used to inform decision-making, please respond to replicators! (Another case was my replication of Atwood 2022 on the long-run economic effects of the measles vaccine.)
Again, read my full comment here. Please support my work by becoming a paid subscriber.
They used many to many merges?
Great work, thank you. Astonishing that this kind of thing isn't standard practice, and that academics can get away with ignoring it and keep their careers.